
Dr. Prof.\ Ali Ezzat Salama
Eng.\ Ahmed M. Essawy & Eng.\ Ahmed M. Ismail
Electronics & Communications Dept., Faculty of Engineering, Cairo University, Egypt.
INTRODUCTION
The Two Dimensional Discrete Cosine Transform (2D-DCT) is considered the most efficient technique in image encoding and compression schemes, being used as a standard in several applications, as well as The Two Dimensional Inverse Discrete Cosine Transform (2D-IDCT) in decoding process.
The DCT is characterized by consuming less power than other transformations like The Discrete Fourier Transform (DFT) which consumes large power, and that is because the DFT is represented by real and imaginary parts unlike the DCT which is represented by the real part only. Besides there is a good reason for using the DCT in a data compression system. The DCT coefficients have been shown to be relatively uncorrelated, and this makes it possible to construct relatively simple algorithms for compressing the coefficients values.
The reason for the decorrelation of the DCT coefficients can be perfectly understood from the following argument: Suppose a perfectly flat line of data is transformed using a 1D-DCT. The data are perfectly correlated and since there is no oscillatory behavior. Only the DC coefficients are present in the transform. In this instance the DCT concentrates or compacts all of the energy of the image into just one coefficient, and the rest are zero. This is what we call Energy Compaction
Tables 1 and 2 illustrate an example of energy compaction.
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
Table 1 Pixel Luminosity Values for a white 8x8 Image Block
510 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Table 2 Transform Domain Coefficients for a White 8x8 Image.
The values of table 2.1 represent the Pixel luminosity values, which represent an all-white 8x8-pixel block.
The transform domain coefficients of the white block provide a good illustration of the energy compaction property of the 2D-DCT. The signal energy is concentrated in the first coefficient and all other coefficients are zero and may be considered redundant when coding. By coding, the image can be described as having a magnitude of 510 at pixel (0,0) and zero elsewhere. This significantly reduces the length of description required to represent the image.
Although both DCT and IDCT are different in the functionality, we cannot say that we have main differences between the 2D-DCT and the 2D-IDCT designs.Both designs are similar except some differences.
To show the difference, we must first take a look at the 2D-DCT equation:
As for the 2D-IDCT equation, it's typically like the 2D-DCT equation but instead of summing on 'n1' & 'n2', we summate over 'k1' & 'k2'. We must consider the mismatch in The DCT which can be seen when performing the 2D-IDCT, we can see that the matrix is scaled by a factor of ~4 which must be multiplied by the entire matrix to get the original matrix.
Another difference exists, when calculating the DCT coefficients from the pixel values & transform it back in the IDCT, is the number of bits required in each case which can be illustrated in table 3.
2D-DCT |
2D-IDCT |
|
The Number Of Input Bits |
8 Bits |
10 Bits |
The Number Of Output Bits |
10 Bits |
8 Bits |
Possible ROM Values |
Results from the possible combinations of the Cosine Matrix Rows |
Results from the possible combinations of the Cosine Matrix Columns |
Table 3 the main differences between DCT & IDCT data representation.
Since we are dealing with video signals then we must have an idea of the standard data rates before & after compression, which can be illustrated in table 4.
Video Resolution (Pels x Lines x Frames/sec) |
Uncompressed Bit rate |
Compressed Bit rate |
|
NTSC video PAL video HDTV video HDTV video ISDN videophone |
(480 x 480 x 29.97HZ) (576 x 576 x 25HZ) (1920 x 1080 x 30HZ) (1280 x 720 x 60HZ) (352 X 288 X 29.97HZ) |
168 Mbits/s 199 Mbits/s 1493 Mbits/s 1327 Mbits/s 73 Mbits/s |
4 : 8 Mbits/s 4 : 9 Mbits/s 18 : 30 Mbits/s 18 : 30 Mbits/s 64 : 1920 Mbits/s |
Table 4 Uncompressed Vs Compressed Bit rate
ALGORITHM
The 2D-DCT equation used in implementation can be written in the form:
Eqn. 2
For 0 £ k1 £ N1-1
0 £ k2 £ N2-1 Otherwise Cx (k1,k2) = 0.
e
k = (1/Ö 2 ) for k = 0.
= 1 otherwise
Where: · N1 is the number of rows in the input matrix.
· N2 is the number of columns in the input matrix.
· n1 is the row index in the input matrix.
· n2 is the column index in the input matrix.
· k1 is the row index in the output cosine matrix.
· k2 is the column index in the output cosine matrix.
· X (n1, n2) is the time domain data.
· Cx (k1, k2) is the transform domain coefficient.
From the above equation, it is obvious that to calculate one transform coefficient we need (N1. N2) additions and (N1. N2) multiplication. There are (k1. k2) transform coefficients, which totally needs (N1. N2. k1. k2) additions and (N1. N2. k1. k2) multiplication. For the case where the output transform coefficients matrix has the same dimensions as the input data matrix, we will have k1 = N1 and k2 = N2.
Thus to calculate all the transform domain coefficients, we need (N1N2)² additions and (N1N2)² multiplication, which is a large number of calculations leading to big delay.
In order to solve and implement the above algorithm efficiently, equation 2, may be examined to give us an important conclusion. This conclusion is that equation 2 is in fact an orthogonal, even symmetrical equation. This fact will help us to reconstruct equation 2 in a manner to save on the number of calculations required through braking up this equation as illustrated below in equation 3.
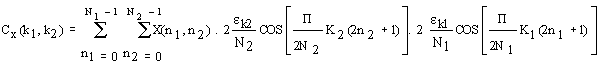
Eqn. 3
Thus the Two Dimensional formula in equation 4.1 is broken up to become two identical One Dimensional equations.
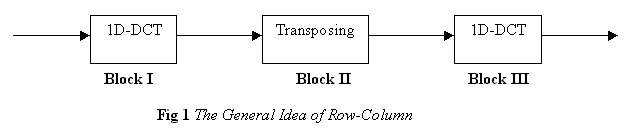
Hence, the 2D-DCT can be calculated by first calculating the 1D-DCT of the rows and then calculating the 1D-DCT of the resulting columns.
This procedure is called “The Row-Column Decomposition” algorithm. The calculation of each 1D-DCT requires (N²) additions and (N²) multiplication.
The Row decomposition requires (N2. N1²) multiplication and additions and the Column decomposition require (N1. N2²) multiplication and additions.
So to get the total 2D-DCT, it requires (N1. N2[N1+N2]) multiplication and additions. So using the Row-Column decomposition algorithm, the number of calculations are logically reduced.
For N1 = N2, the ratio of saving of calculations = (N². N²) / (2.N³) = N/2.
The even symmetrical formula of equation 3 can be rewritten as:
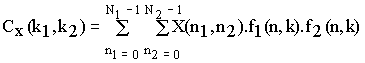
Eqn. 4
As shown, the quantity (Fi) is a function only in (n) and (k). Thus the possible numerical values for the quantity (Fi (n, k)) can be calculated separately independent on the summation forming a matrix which is called The Cosine Matrix.
These numerical values depend only on the dimensions of the output transform coefficients matrix (k1 and k2) and the dimensions of the input data matrix (N1 and N2). Starting the possible values in a cosine matrix from accessing its values when needed is considered largely a very efficient way to get the 1D-DCT because this saves large time taken during calculating the values of F (n, k).
Hence, the possible values calculated for F (n, k) are:
For the 8x8 Block 2D-DCT:
n = 0 |
n = 1 |
n = 2 |
n = 3 |
n = 4 |
n = 5 |
n = 6 |
n = 7 |
|
K = 0 |
0.177 |
0.177 |
0.177 |
0.177 |
0.177 |
0.177 |
0.177 |
0.177 |
K = 1 |
0.245 |
0.208 |
0.139 |
0.049 |
-0.049 |
-0.139 |
-0.208 |
-0.246 |
K = 2 |
0.231 |
0.096 |
-0.096 |
-0.231 |
-0.231 |
-0.096 |
0.096 |
0.231 |
K = 3 |
0.208 |
-0.049 |
-0.245 |
-0.139 |
0.139 |
0.245 |
0.049 |
-0.208 |
K = 4 |
0.177 |
-0.177 |
-0.177 |
0.177 |
0.177 |
-0.177 |
-0.177 |
0.177 |
K = 5 |
0.139 |
-0.245 |
0.049 |
0.208 |
-0.208 |
-0.049 |
0.245 |
-0.139 |
K = 6 |
0.096 |
-0.231 |
0.231 |
-0.096 |
-0.096 |
0.231 |
-0.231 |
0.096 |
K = 7 |
0.049 |
-0.139 |
0.208 |
-0.245 |
0.245 |
-0.208 |
0.139 |
-0.049 |
Table 5
An important note must be declared here, The 2D-IDCT equation have the summations on 'k1' & 'k2' not 'n1' & 'n2' which can be interpreted, in matrices form, as the transposed matrix of the 2D-DCT possible values of cosine matrix.
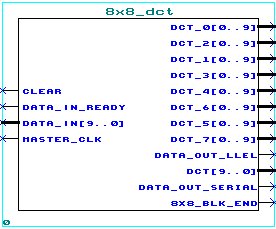
HARDWARE IMPLEMENTATION
The hardware chosen for implementation of the DCT algorithms is the Field Programmable Gate Array (FPGA) which has widespread use in the development of Application Specific Integrated Circuits (ASICs).
The design is implemented on FPGA using Altera Max Plus II. We designed these blocks, along with the internal ones, using GDF & VHDL modules.
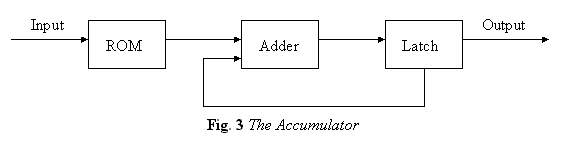
To improve the performance, we used the Distributed Arithmetic Algorithm.
The Distributed Arithmetic (DA) is an efficient procedure that targets the sum of products. In our design, each element in the input data matrix is taken 10 bits. Since each element in the input data matrix is implemented as 10 binary bits, it can be written as....
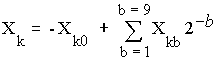
Eqn. 5
Where:
- Xk0 = 1for negative number
= 0 for positive number
- Xkb is the binary bit that taken a value ‘0’ or ‘1’.
- Multiplying by (2-b) means shifting right (b) bits.
For every row [r] in the 4x4 DCT:
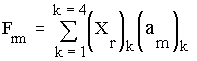
Where:
- (Xr)kis the element (k) in row [r] in the cosine matrix.
- (am)kis the value (k) in row [m] in the cosine matrix.
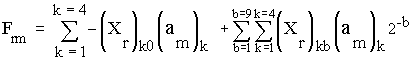
By substituting with Xk from equation 3.1 we get
= - [(Xr)10.(am)1 + (Xr)20.(am)2 + (Xr)30.(am)3 + (Xr)40.(am)4]
+ [(Xr)11.(am)1 + (Xr)21.(am)2 + (Xr)31.(am)3 + (Xr)41.(am)4] 2-1
+…
+ [(Xr)19.(am)1 + (Xr)29.(am)2 + (Xr)39.(am)3 + (Xr)49.(am)4] 2-9
This block is responsible for the bit formatting in an appropriate way to be able to address the DALUT ROM's to calculate the result of the 1D summations (1D-DCT)
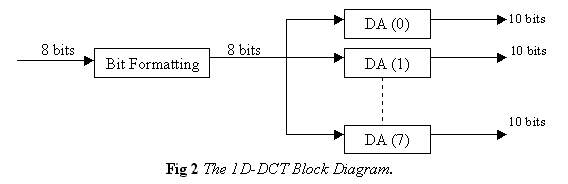
Bit Formatting Block:
Calculation of the 1D-DCT (DA):

SIMULATION RESULTS
To give an overview about how the interface to our design is done and how to test our results. Both were done using a single visual basic program.
By interface we mean how to input the data to the hardware. Our input data is a matrix, each value represents the luminance value of the image pixels.
The program is divided into two parts:
This part takes the input data (luminance values) from a text file (datain.txt) and applies the DCT equation to obtain the DCT coefficients and output them to a file (dct.txt).
At the same time it sends this input data to the circuit to obtain the DCT coefficients.
The results from our circuit and from the software program are compared to check for errors.
This part takes DCT coefficients from dct.txt file, applies the IDCT equation to obtain IDCT coefficients and stores them into idct.txt file. At the same time it sends these DCT coefficients to the circuit to obtain the IDCT coefficients. The results from our circuit and from the software program are compared to check for errors.
N.B:
To send any data to our circuit, it is converted to binary format then sent to the parallel port element by element. From the 10 bits, we send the least significant 8 bits to the port 378 (active high), and the most significant 2 bits are sent to the port 37A (active low). After each element (10 bits) is sent to the parallel port, we send a “1” then a “0” on the most significant bit of port 37A to announce that there is an element ready on the port (this is applied to “Data_Ready” input pin of chip).
Another program were made, using C language, which takes a picture, divided into Pixels each of which has given 8 Bits to represent its luminance value. We used this program to decide how many digits are enough for the cosine values since we are going to store there possible combinations in ROM's. The decision was based on performing the 2D-DCT then the 2D-IDCT then transform the luminance values back into Pixel level to reconstruct the image again.
The decision was based on performing the 2D-DCT then the 2D-IDCT then transform the luminance values back into Pixel level to reconstruct the image again.
As an example for the 8x8 2D-DCT design, we represent an input matrix, ideal DCT matrix and the actual DCT matrix from our design:
255 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
0 |
255 |
0 |
255 |
0 |
255 |
0 |
255 |
Input matrix of Luminance values of Pels.
255 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
8 |
0 |
10 |
0 |
15 |
0 |
42 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
10 |
0 |
12 |
0 |
17 |
0 |
49 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
15 |
0 |
17 |
0 |
26 |
0 |
74 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
42 |
0 |
49 |
0 |
74 |
0 |
211 |
Actual DCT coefficients.
251 |
1 |
0 |
12 |
0 |
0 |
0 |
1 |
0 |
8 |
0 |
9 |
0 |
16 |
0 |
40 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
9 |
0 |
11 |
0 |
16 |
0 |
47 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
14 |
0 |
16 |
0 |
25 |
0 |
70 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
40 |
0 |
46 |
0 |
70 |
0 |
172 |
Output matrix of DCT coefficients.
V. MODIFIED 8x8 2D-DCT / IDCT
To reduce Hardware needed for the previous design, we used a different algorithm. This algorithm by Chen et al uses the symmetry in the cosine matrix to implement the 8x8 1D-DCT / IDCT using two 4x4 1D-DCT / IDCT which reduces gradually the Hardware & increase the maximum speed.
The cosine matrix for the 2D-DCT can be written as shown:
D |
D |
D |
D |
D |
D |
D |
D |
A |
C |
E |
G |
-G |
-E |
-C |
-A |
B |
F |
-F |
-B |
-B |
-F |
F |
B |
C |
-G |
-A |
-E |
E |
A |
G |
-C |
D |
-D |
-D |
D |
D |
-D |
-D |
D |
E |
-A |
G |
C |
-C |
-G |
A |
-E |
F |
-B |
B |
-F |
-F |
B |
-B |
F |
G |
-E |
C |
-A |
A |
-C |
E |
-G |
The symmetry in this matrix can be exploited and the 1D-DCT will then be rearranged to give:
y0 = D D D D * x0 + x7
y2 B F -F -B x1 + x6
y4 D -D -D D x2 + x5
y6 F -B B -F x3 + x4
AND
y1 = A C E G * x0 - x7
y3 C -G -A -E x1 - x6
y5 E -A G C x2 - x5
y7 G -E C -A x3 - x4
The (N x N) multiplication matrix has been replaced by two (N/2) x (N/2) matrices, which can be computed in parallel as can the sums and differences forming the vectors on the right hand side. The implementation requires 32 multiplication instead of 64 multiplication.
To implement the 1D-IDCT, we must use the transposed cosine matrix, which leads to another rearrangement:
y0 + y7 = D D D D * x0
y1 + y6 B F -F -B x2
y2 + y5 D -D -D D x4
y3 + y4 F -B B -F x6
AND
y0 - y7 = A C E G * x1
y1 - y6 C -G -A -E x3
y2 - y5 E -A G C x5
y3 - y4 G -E C -A x7
Adding (y0 + y7) and (y0 - y7) we obtain y0 and subtracting them we obtain y7 and so on for the rest of the 1D-IDCT outputs.
From the previous equation, we can realize that it's the second matrix is the same as in the 1D-DCT since it's a symmetrical matrix. Also, the Hardware implementation for the 1D-IDCT will be simpler since the summation and subtraction are done for the output and not the input as in the 2D-DCT.
An important advantage arises in this design, the maximum allowable speed will increase up to 111.11 MBit/sec since we are using the 4x4 DA multiplication knowing that both parts must work in parallel to save time. This requires dividing the Master Clock signal by two for the 4x4 DA multiplication to compute correctly.
As an example for the 8x8 2D-DCT design, we represent an input matrix, ideal DCT matrix and the actual DCT matrix from our design:
510 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Input matrix of DCT coefficients.
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
255 |
Actual Luminance values of Pels.
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
252 |
Output matrix of Luminance values of Pels.
The average error, between the exact values and the output values from the simulation results, can be found as less than 1.2%
VI. CONCLUSION & FUTURE LOOK
We have made complete design of the 8x8 2D-DCT and 8x8 2D-IDCT designs with 10 input bits for IDCT and 8 input bits for DCT with bit duration of at least 18 nsec, which is equivalent to a max bit rate of 55.55Mbits/sec.
We were unable to put the memory of the DCT & IDCT of the 8x8 Block in a single Altera FPGA chip since the size is. However, this size is reduced due to the symmetry in the cosine matrix, since the cosine is a periodic function.
The Chen et al algorithm (2) helped us reduce the memory size since it transforms the 8x8 1D-DCT / IDCT into two 4x4 1D-DCT / IDCT and increases the speed into 111.11Mbit/sec.
We are currently investigating reducing the number of bit per word to reduce the losses in the memory utilization to use the hardware more efficiently. This has major impact on the memory size needed to use a smaller chip (Altera Flex 10KE EPF10k100).
REFERENCES
Package used:
Altera Max Plus ll.CHIP PARAMETERS
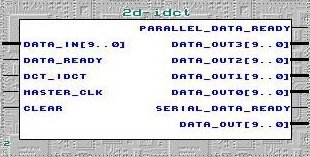
... 4x4 Block Chip Description ...
NAME |
DESCRIPTION |
DATA_IN [9. .0] |
10 bits input data applied element by element For DCT : use the least 8 bits [7 . . 0] For IDCT :use 10 bits [9 . . 0] Input must be hold for a period of 3 Master_Clocks. |
DATA_READY |
Positive edge triggered when each input element is ready on DATA_IN [9 . .0] Bus. |
DCT_IDCT |
Selects between DCT & IDCT. DCT if high & IDCT if low. |
MASTER_CLK |
Input clock of the chip. For 4x4 block, at least 60nsec period. |
CLEAR |
Set high for one clock period before using the chip. |
DATA_OUT 3 [9. .0] DATA_OUT 2 [9. .0] DATA_OUT 1 [9. .0] DATA_OUT 0 [9. .0] |
Parallel data outputs as a row starting from ‘data out 0’ to ‘data out 3’ |
PARALLEL_DATA_READY |
A pulse is generated when the parallel data is ready. |
DATA_OUT [9. .0] |
Serial data output as element by element. |
SERIAL_DATA_READY |
A pulse is generated when the serial data is ready. |

